
首页
-
玩转JetBot自动驾驶 (七)实现自动避障
最近,能自动驾驶的JetBot挺多人关注的,就有小伙伴问小编:“树莓派的摄像头能不能用呢?”小编没多想,就说可以啦(因为小编的JetBot正用的是树莓派v2摄像头)。万万没想到,问的是树莓派v1系列的。很遗憾回答小伙伴,暂时NVIDA官方没有要支持使用OV5667芯片并已经停产的树莓派v1系列摄像头的计划。

-
玩转JetBot自动驾驶 (七)实现自动避障
本篇为本入门系列的最后一篇,一共7篇教程,能完整地让JetBot通过摄像头实时自动避障。

-
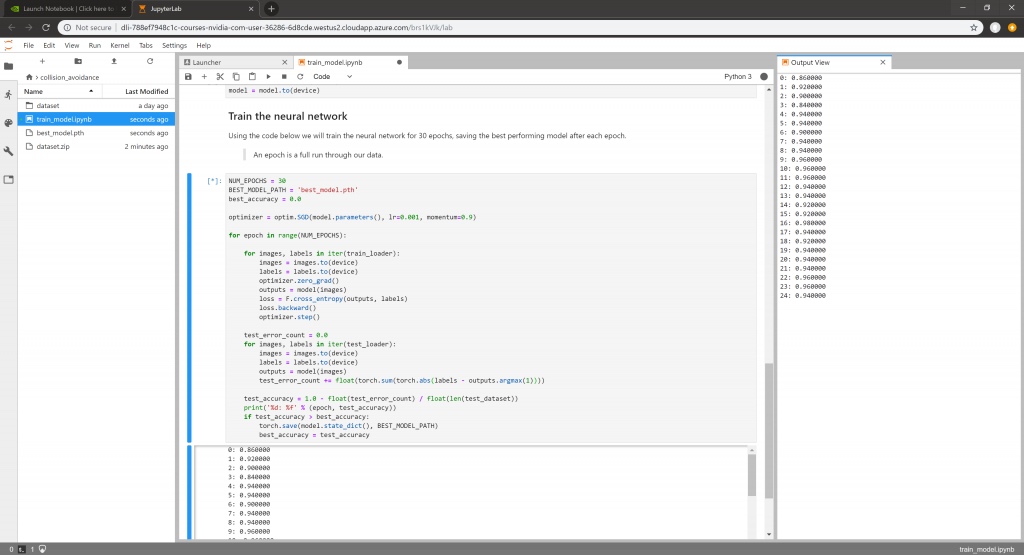
玩转JetBot自动驾驶 (六)训练JetBot自己认识危险
在训练之前,建议你把JetBot关机,使用一个5V,3A的充电头或专用电源给JetBot供电。不建议使用移动电源,因为在训练的过程中会消耗很多资源很费电,如果嫌麻烦的请把移动电源充满电,以免在训练在训练过程中没电了,白费劲了。
-
玩转JetBot自动驾驶 (五)通过采集数据教JetBot如何认识危险
如果你学会了通过基础移动的notebook实现jetbot的行走,那就太了不起了。 但其实更了不起的是让jetbot独自行走。
这将会是一个超级难的任务,有许多不同的处理,但所有的问题通常会分解成更容易的子问题。
而最重要的解决的问题是防止jetbot发生危险的情况,我们称之为避障。 -
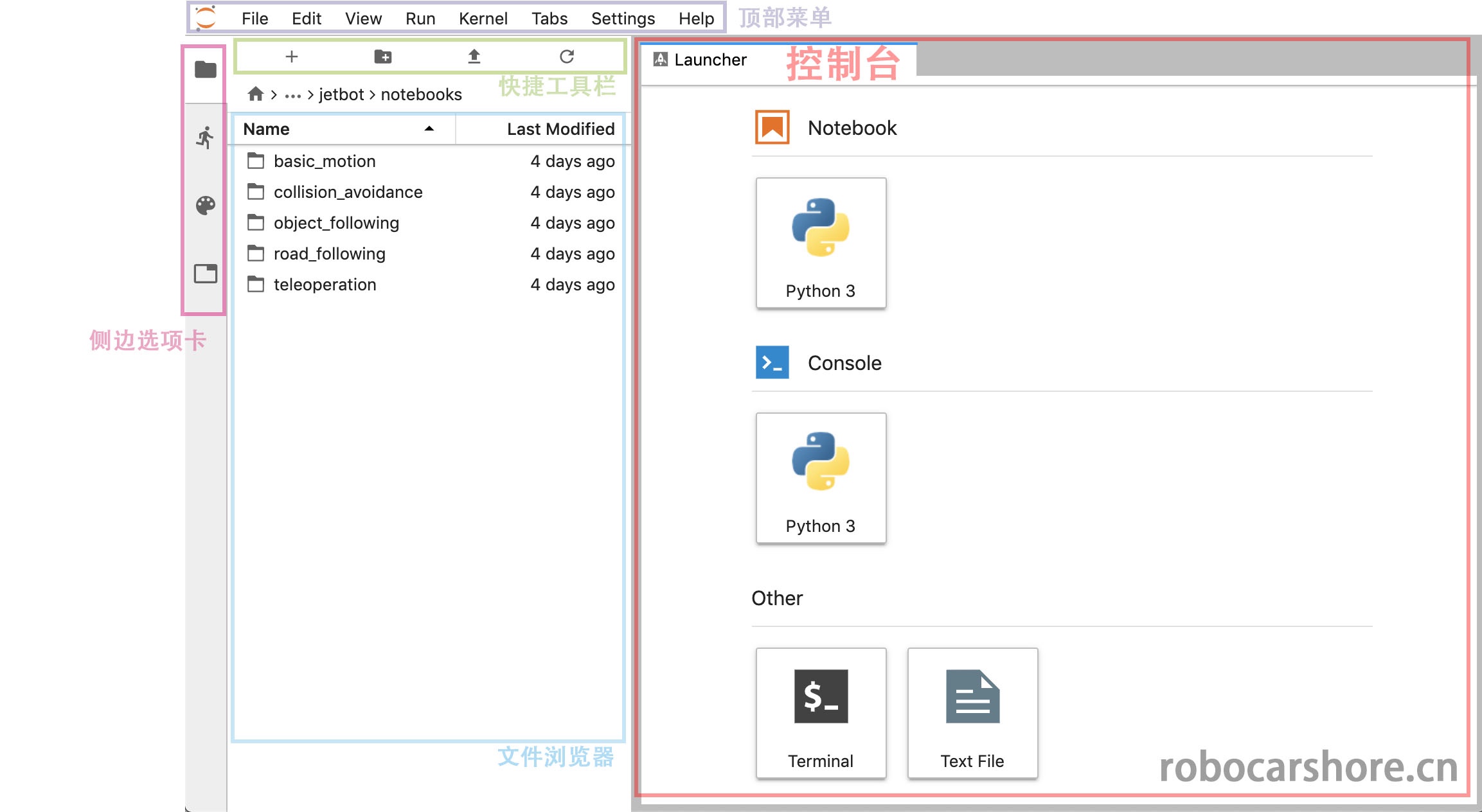
玩转JetBot自动驾驶 (四)开动你的JetBot
本篇详细讲解,如何使用jupyter lab在浏览器上控制你的JetBot,如何通过python进行对JetBot的编程。
-
玩转JetBot自动驾驶 (三)系统安装与配置
在上一篇文章中,我们完成了JetBot的硬件安装。现在,我们将继续完成JetBot的系统安装和配置。这个过程包括刷写JetBot的SD卡镜像、启动Jetson Nano,并进行一些必要的设置,以确保JetBot能够正确运行。请按照以下步骤完成这些操作。
